1. 1차원 벡터, 리스트에서 중복제거
- unique() 사용
a = rep(1:10, each = 2)
print(a)
unique(a)
2. Data frame에서 중복 제거
- duplicated() 사용
- 데이터 프레임 생성
DUPLICATE <- data.frame(obs = 1:10,
name = c("A","A","B","A","C","C","D","D","E","E"),
id=c("A10153","A10153","B15432", "A15853","C54652","C54652",
"D14568", "D17865", "E13254","E13254"),
data = c("2018-11-30", "2018-11-30","2018-11-30",
"2018-11-29","2018-11-28","2018-11-27","2018-11-28",
"2018-11-27", "2018-11-26", "2018-11-25"),
btw = c(1,3,4,5,5,6,7,3,2,3),
ffm = c(7000,6353,9123,5423,8235,7345,5234,9453,8453,5535)
)
DUPLICATE
2-1 전체 중복제거
duplicated(DUPLICATE) # 중복되는 행일 경우 True 값 반환
# 중복되는 행의 위치를 which() 함수로 찾은 후, 그 위치가 아닌 행만 추출
DUPLICATED3_1 <- DUPLICATE[-which(duplicated(DUPLICATE)), ]
2-2 변수 한 개를 기준으로 중복제거
# name이 중복인 행을 제외하고 출력
DUPLICATED3_2 <- DUPLICATE[-which(duplicated(DUPLICATE$name)), ]
2-3 다변수를 기준으로 중복제거
# name, id 두 개의 값이 같은 중복 데이터 제거
DUPLICATED3_3 <- DUPLICATE[!duplicated(DUPLICATE[,c('name','id')]), ] # 변수명으로 제거
DUPLICATED3_4 <- DUPLICATE[!duplicated(DUPLICATE[,c(2,3)]), ] # 인덱스명으로 제거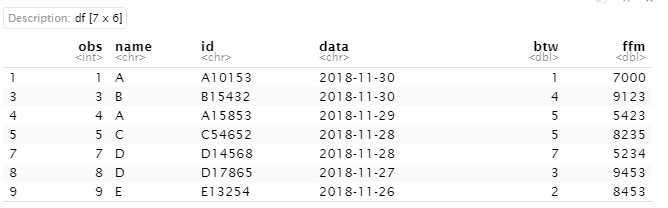
- dplyr 패키지의 distinct()
# distinct(dataframe, 기준변수1, 기준변수2,...)
distinct(DUPLICATE, name, id)
더보기
참고 서적 / 위키북스|Must Learning with R (개정판)
'R > preprocessing' 카테고리의 다른 글
| R | 전처리 | 결측치 처리 (0) | 2022.12.05 |
|---|